
每次预计到达时间的延误都会引发连锁反应:码头延误、船员闲置、生产中断以及客户失望。 准确的到货时间对供应链效率至关重要,因为能够更好的规划、协调和资源分配,并在整个物流网络中进行资源分配。
可靠的 ETA 使企业能够预测延误、减少等待时间、优化仓库和码头运营,并按时向客户交付。 其结果是客户满意度提高、运营成本降低,以及生产停工或库存缺货等中断情况减少。 挑战在于,预测卡车货运的 ETA 需要强大的机器学习模型,该模型应捕捉影响 ETA 的诸多细微差别特征,包括天气、交通、季节性、车道差异、运营细微差别甚至人类行为。
解开整车 ETA 问题
与包裹或小包裹运输不同,整车旅程的可变性远超“在路上的时间”。 货运时间表包括:
- 停靠之间的驾驶时间。
- 在设施(如仓库或堆场)等待装载、卸载或文书工作的停留时间。
- 短暂的燃料、用餐或小憩。
- 过夜或长时间休息。
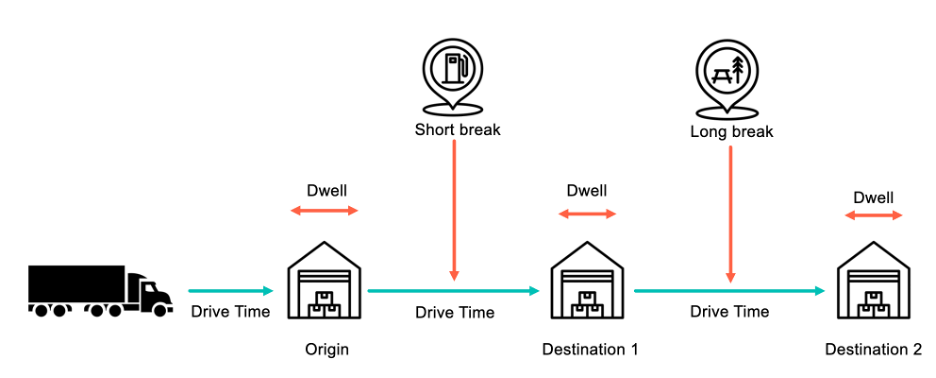
在短途旅行中,单一设施延误可能会扰乱时间表。 在长途运输中,强制性休息或意外停留可能更为重要。 这些只是可控制的因素——交通拥堵、天气事件和堆场拥堵都增加了又一层不确定性。
数据质量差距(GPS信号不稳定、缺少里程碑更新)、数千条航线的车道级别变化性以及承运商和设施之间的运营差异,使问题更加复杂。 简单的基于距离的模型无法捕捉这种复杂性。
我们如何衡量 FTL ETA
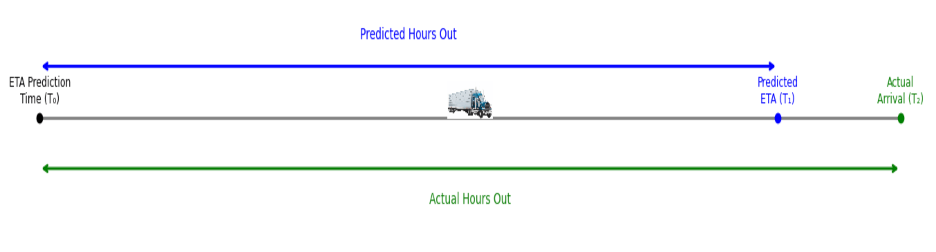
为了衡量 ETA 准确性,我们跟踪两个互补指标:实际运行时间和预测运行时间。
这些措施不仅凸显了 ETA 的准确性,还凸显了其提供的提前通知程度,在真实世界运营中平衡了准确性与实际有用性。
为什么预测准确的 ETA 如此困难?
要实现更准确的 ETA,就必须系统地解决以下问题:
- 数据质量问题:ping 覆盖范围存在差距、位置信号质量低,里程碑更新不完整,降低了可靠性。
- 货运路线可变性:路线和行程长度差异很大,多式联运(例如卡车-铁路-卡车)增加了复杂性。 每条线路的行为都不同,因此难以构建一个在多元化网络中表现良好的单一模型
- 计划外停留:司机休息、设施延误或堆场拥堵可能会以不可预测的方式大幅延长行程。
- 外部中断:天气事件和交通拥堵变化很大,难以预测。
- 运营细微差别:承运人/承运商行为、司机习惯的差异以及对设施运营时间的可视化程度低,都影响了结果。
- 系统性错误驱动因素:过度停留区域、错过里程碑、路线偏差和数据差异往往会导致 ETA 持续不准确。
这些挑战凸显出为什么 ETA 建模需要强大的数据管道、自适应模型、持续的错误分析和监控,才能在真实世界物流中保持准确性。
从原始数据到可靠的 ETA:端到端视图
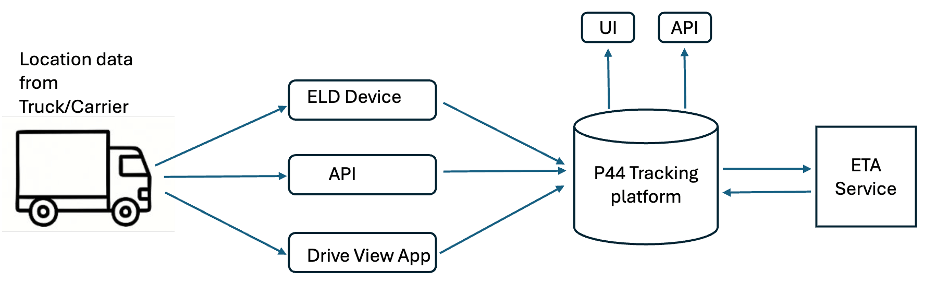
要了解 ETA 预测是如何进行的,您需要从旅程本身开始。 首先,卡车从发点运往目的地,然后随着位置更新或里程碑完成等事件发生,该信息会传输到 project44 跟踪系统。 这些数据主要通过三种方式获取:
- 卡车上安装的 ELD 设备持续发出 PING。
- EDI/API 直接与承运商集成。
- Drive View 移动应用程序,可共享司机手机的位置数据。
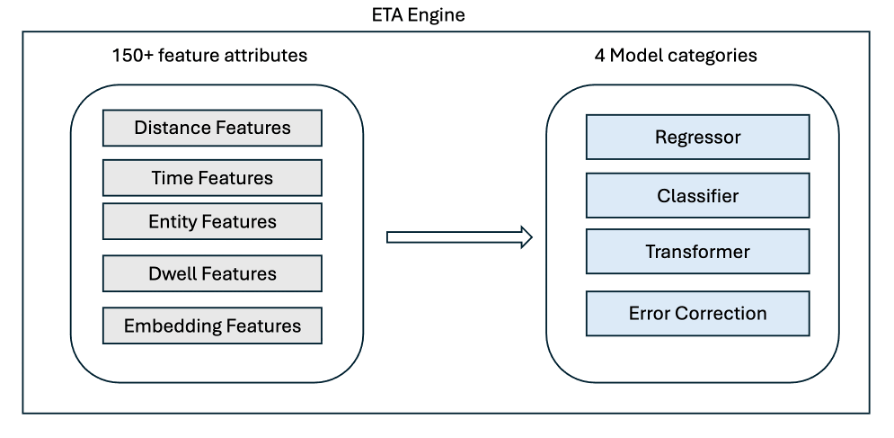
所有这些信号都将录入 project44 跟踪平台,然后传递给 ETA 服务,由数据科学模型生成预测。 ETA 服务每次收到新地更新时,都会使用多个专有模型重新计算预测,包括回归器、分类器、变换器和误差纠正框架,由 150 多个输入特征提供动力。
预测的预计到达时间 (ETA) 然后发回 project44 平台,显示在跟踪 UI 中,并通过 webhook 交付给客户,以实现实可视化。
project44 如何以不同的方式处理 ETA
过去一年,我们在 500 多家 FTL 货运商的大型租用计划中试验并部署了多种模式。 我们总共交付了超过10种生产就绪的模型,每种模型都旨在捕捉整车货运的不同变动因素。 其结果是一个分层的ETA引擎,能够适应现实世界的复杂性,并始终如一地提供更高的ETA预测准确性。
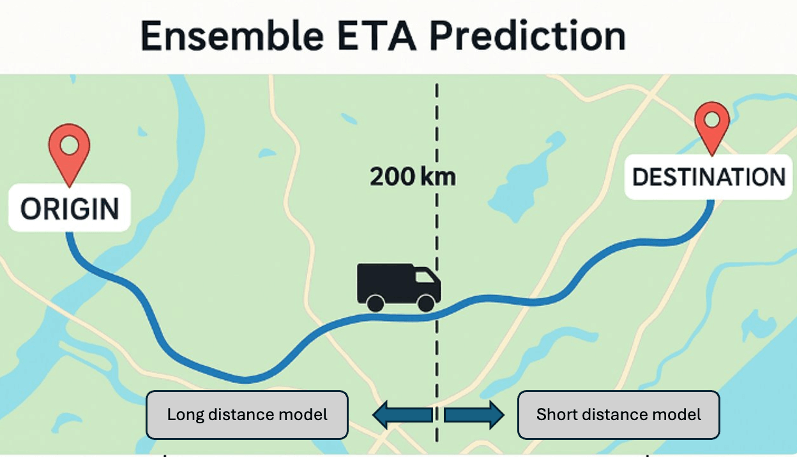
1. 集成模型
短途和长途运输方式有很大不同。 短途运输 (<200 公里) 通常在一天内完成,通常由一名司机驾驶,中断时间最少。 但长途运输 (>200 公里) 通常跨越多天,并且包含重要的强制性休息时间,难以预测和建模。 通过训练每种模式的专业模型,并将它们的预测合并到统一的输出中,我们捕捉到了两种旅行类型的独特行为,以提高预测准确性。
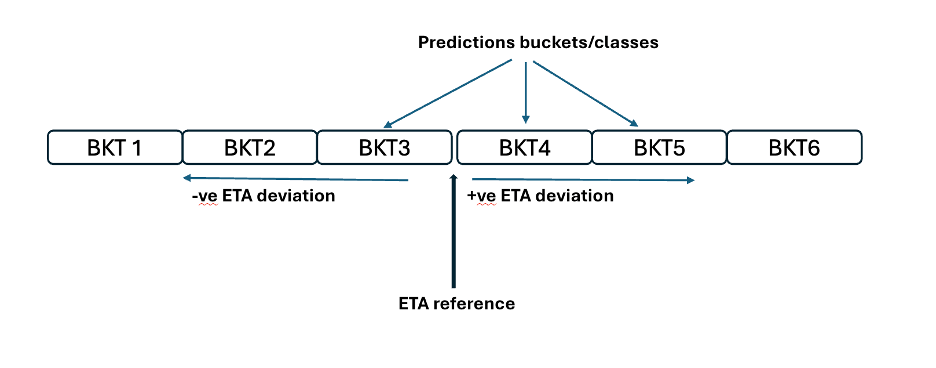
2. 分类器模型
虽然整体模型改善了 ETA 预测,但在可变性高的情况下仍举步维艰,例如不一致 dwell 行为或车道级别差异,因为它生成了单点估计。 为解决这一问题,我们设计了基于分类器的方法。 该模型不会预测一个确切的 ETA,而是以参考 ETA(例如历史运输时间中位数或预定时段的中点)为起点。 然后,我们计算残差(实际 ETA 和参考值之间的差异),并将这些残差归入范围。
分类器的工作是预测最终 ETA 将归入的类别(或类)。 识别桶后(例如 BKT2),预计到达时间 (ETA) 的计算公式为:
最终 ETA = 参考 ETA + 预测桶的中点
这种桶式方法使模型能够更好地捕捉变化性,并在部署时合理提高准确性。
3. 变压器模型
深度学习为 ETA 预测提供了明显的优势,尤其是大规模模拟复杂模式的能力。 Transformer 模型根据近一年的货运数据训练,非常自然地契合。 它们的关键优势在于注意力机制,使该模型能够专注于最相关的信号,例如交通高峰、停留热点或路线偏差,这些信号对 ETA 的准确性影响最大。
与独立处理特征的基于树的方法不同,Transformer 在上下文中动态权衡每个 ping 和事件的重要性。 这一功能显著提高了准确性,并使模型能够泛化到数千条车道。 由于这些收益,Transformer 现在成为我们未来 ETA 开发的基准架构。
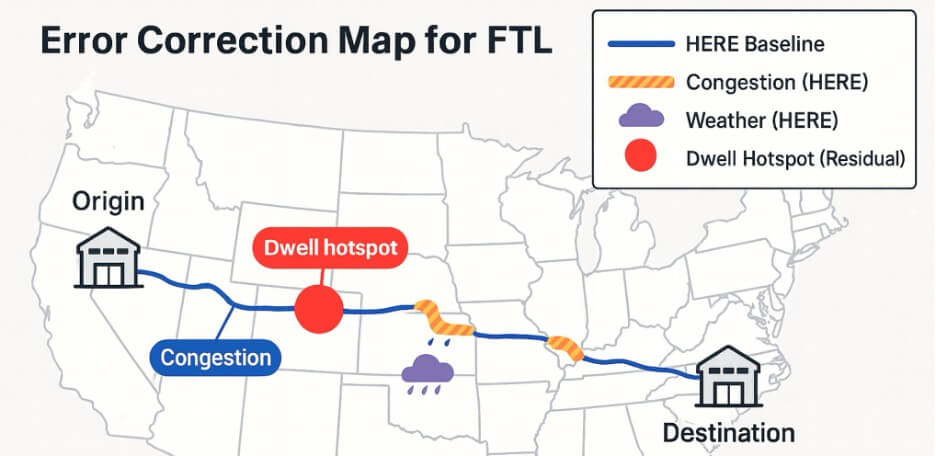
4. 错误纠正模型
纯驾驶时间模型的局限性,例如停留、中断和设施延迟,可以通过学习残余误差来解决。 我们首先使用伪确定性 HERE Maps 基准,以估计理想条件下的纯驾驶时间。 然后,辅助机器学习模型预测因停留、承运人/承运商行为或中断事件引起的残余延误。 在 Transformer 模型上叠加误差校正,使准确率额外提高 8–10 个百分点。
我们取得的成就
过去一年,我们已为 500 多家 FTL 货运商部署了 10 余款生产就绪的模型。 成果:在 10 小时预测范围内(±2 小时窗口期)准确性提高了 28 个百分点。
对于货运商而言,这一改进意味着规划更可靠、意外情况更少、以及足够的交货时间来做出主动决策,无论是重新分配码头劳动力、调整库存,还是重新安排货运路线以避免中断。
关键客户的绩效
虽然全球 ETA 模型适用于许多货运商,但一些客户的运营模式独特,需要量身定制的方法。 以下几个示例展示了灵活建模如何实现实际影响:
高容量短途托运人(欧洲):
该客户每天的卡车全运量非常高。 这些旅行主要由相同的司机沿用一致的路线,导致变动性较低。 我们观察到基于 HERE Maps 的残差分布非常紧密,并部署了变压器模型用于预测残差。 该解决方案显著提高了准确性,将准确性提高了 20-25 个百分点。
多站托运人(北美):
这家客户的独特之处在于,他们的货运涉及多站运输,有时多达 14 个站点。 这种行为与我们的主要模型训练时的情景有很大不同。 我们试验了多种方法,最终开发出一个启发式模型来预测每个停留。 利用 HERE Maps 运输时间和基于启发式计划停留模型的综合预测,准确率提升了超过 35 个百分点。
长途隔夜承运人/承运商(北美):
这家关键客户运营了非常长的隔夜旅行,并且在计划地点有较长的停留时间。 我们通过将具有相似长途旅行和多站模式的租户进行分组,开发了专用模型。 我们设计了与停留时间相关的功能,例如停留时间中位数和特定于车道的停留特性。 这种专业模型的总体准确率提高了 8 个百分点。
到目前为止,我们学到了什么?
01
数据质量决定准确性:
当位置信息频繁、准确且广泛传播时,到达时间就更可靠。 数据薄弱导致绩效不佳。
02
漂移是持续的:供应链每周都会发生变化,因此定期进行再培训和漂移监控对于保持模型与最新模式一致至关重要。
03
不再“一刀切”:多式联运(铁路 + 卡车)、多站运输以及短途和长途运输的专用模型提供了明显的改进。
04
Transformer 是一次阶梯性的变革:投资于 transformer 架构,升级基础设施以训练更大的模型,显著改善了通用性和性能。
05
处理计划外事件很重要:未计划的/周末长时间停留,以及错过/更改约会是导致错误的主要原因,需要仔细进行特征工程。
06
错误纠正可带来提升:错误纠正方法(例如,在 HERE/计划基准的基础上建模)等替代建模技术使 ETA 准确性大幅提高。
07
坚实的基础放大一切:主动监控、再培训规范以及更广泛的历史资料记录都已实现模型复合改进。
展望未来
即使准确率提升了 +28pp,我们也不会止步于此。 旨在进一步推动 ETA 绩效的几项举措已启动:
- 租户感知后处理。 我们正在增加一个轻量级层次,将单一的全球模型调整为租用计划,为相似的货运商微调输出,而不是为每个货运商制定单独的模型。
- 租用计划配置器。 一个新模块将通过共享运营模式(车道、服务级别、停留行为)来聚类相似的租户,为上层的后处理层提供支持。
- 大规模分布式训练。 我们正在投资分布式训练框架,以实现跨节点学习的并行化,从而使模型能够在更大的历史语料库上进行训练,更快地收敛并更好地泛化。
- 更深入的可解释性。 我们正在扩展可解释性堆栈,以清晰显示预测或更改的原因(例如“由于长时间停留,ETA 调整后 +3 小时”),从而建立透明度和信任。
这些举措通过强大的机器学习运营纪律和情境解释补充了核心模型,进一步提高了 ETA 的准确性。


